How Documents are Identified
- First Page Identification Conditions
- Last Page Identification Conditions
- The Keep each entry/file as a separate document option in Universal Capture or Laserfiche Capture Engine. This option keeps different scanned documents separated from each other.
- A defined document length within Quick Fields
When more than one of these properties is configured, they will all interact together.
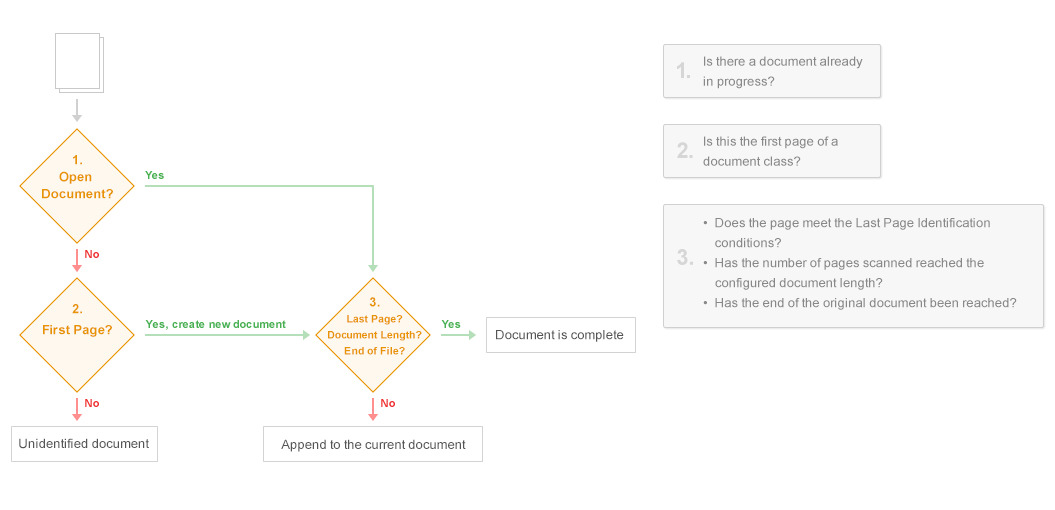
The Process of Identifying Pages as Documents
When scanning pages, Quick Fields first determines if the incoming page belongs to an already identified document in progress. If you are only using First Page Identification to identify documents, Quick Fields will compare every scanned page to the First Page Identification conditions to see if that page is the first page of a new document. A page belongs to a document in progress if another page scanned before it was identified as the first page of the document and the current page has not met any First Page Identification conditions. If a previously scanned page has been identified as the first page of a document, the incoming page is appended to the document in progress, and this process repeats until the document is complete.
If the page being scanned belongs to a document already in progress, Quick Fields checks to see if it's the last page of the document using one or a combination of the following options:
- Last Page Identification Conditions
- A defined document length within Quick Fields
- The Keep each entry/file as a separate document option in Universal Capture or Laserfiche Capture Engine. This option keeps different scanned documents separate from each other.
If the page being scanned does not belong to a document already in progress (e.g., if it's the first page being scanned since a previous document was completed) Quick Fields determines if it meets any First Page Identification conditions, making it the first page of a new document. If First Page Identification conditions are not configured or the page does not meet any of the conditions, the document will become an unidentified document.
Interaction Between Options
Below is a table displaying how these different options interact when configured together.
| First Page Identification | Last Page Identification |
Keep each entry/file as a separate document |
Limit documents to __ pages | Behavior |
|---|---|---|---|---|
| ● | Compares every scanned page to First Page Identification conditions to find the first page of each document. | |||
| ● | ● | Compares every scanned page to First Page Identification conditions to find the first page of each document. A new document will be created if it reaches the end of the original file, or it finds the first page of a new document using First Page Identification conditions. | ||
| ● | ● | Identifies the first page using First Page Identification conditions and appends each following page until the document length configured in Quick Fields is met. | ||
| ● | ● |
Identifies the first page using First Page Identification conditions and appends all the following pages. Each page (including the page identified as the first page of the document) is compared to the Last Page Identification conditions. Once a page matches the Last Page Identification conditions, the document will be closed and the next page scanned will be compared to the First Page Identification conditions again to find the beginning of the new document. |
||
| ● | ● | ● |
Identifies the first page using First Page Identification conditions and appends all following pages until
|
|
| ● | ● | ● |
Identifies the first page using First Page Identification conditions and appends all following pages until
|
|
| ● | ● | ● |
Identifies the first page using First Page Identification conditions and appends all following pages until
|
|
| ● | ● | ● | ● |
Identifies the first page using First Page Identification conditions and appends all following pages until
|
Example: This example uses the document length configured in Quick Fields and Keep each file as a separate document options.
Blair Inc. uses Universal Capture to scan and process contracts. Each contract has 25 pages. The last page in each contract is a signature page they want to separate from the other 24 pages. To do this, they select Keep each file as a separate document so when the contracts are scanned, they will be separated by each contract's original number of pages (25). Under Last Page Identification, they select Limit documents to __ pages and configure the page limit to 24. This will end the document after 24 pages. When they start scanning, the page limit will be reached first and the contract will be ended at 24 pages. It continues to scan and since the next page is the 25th page, it will end the document again since 25 was the length of the original file. This will result in the 24-page contract as one document and the 1-page signature document as another document.
Example: This example uses Last Page Identification conditions only.
Earl Inc. scans a stack of purchase orders (in paper form) into Quick Fields. Each purchase order is a different length. Every page of the purchase order has "Page X of Y" where "X" is the current page and "Y" is the total number of pages in the document. They know the "X" and "Y" on the last page of the document will match. They use an OmniPage Zone OCR process and add two zones, one to read the value of "X" and the other to read the value of "Y." A Token Identification process can then be used to compare the two values. If they match, the scanned page is the last page.
Note: You can find more examples in the Document Length topic.