Each process that can be used for First Page Identification has its own set of properties. In most cases when configuring a First Page Identification process, you will need to determine which properties a document must match to be identified — these are the identification conditions. When a page meets these conditions, it will be assigned as the first page of a new document in that document class.
Note: If the identification process depends on the results of some other process, you will need to configure that process first.
Example: Text Identification examines the text associated with a page. If text is not already associated with the pages you will scan, you will need to configure OCR or Text Extraction in Pre-Classification Processing to generate the text.
Example: Token Identification examines the tokens associated with a page. Configure processes that generate tokens in Pre-Classification Processing to use their values in Token Identification.
To configure a process in First Page Identification
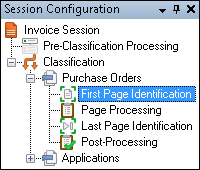
- In the Session Configuration Pane, select the First Page Identification stage under the
 name of the document class the documents will be assigned to.
name of the document class the documents will be assigned to. - In the Tasks Pane, select the name of the process.
- Configure the properties of the process. For more information, use the wizard and the help files for that process.
- When you encounter the Identification Condition property, follow the steps described in the Identification Conditions section of the help files.
- Optional: To test the configuration, select Test Processes or Test Current Process. For the best results, add a custom sample page before testing. Adjust and test until you are satisfied with the results.
Note: First Page Identification processes will all be configured using the sample page configured as the first sample page, not the default sample page. If there is no first sample page configured, the default sample page will be displayed.